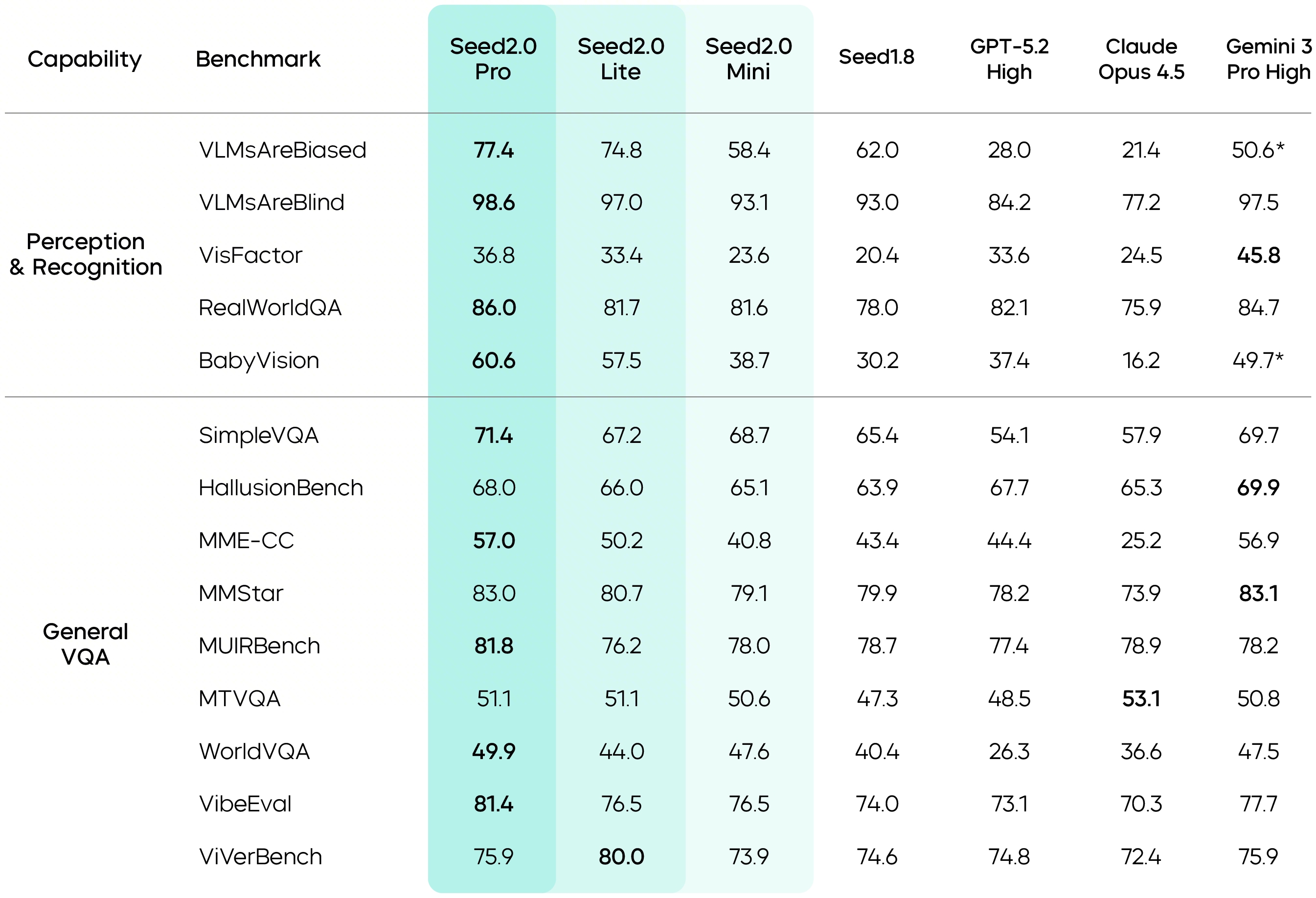
ByteDance’s Seedance model family has evolved rapidly. Seedance 1.0, released in mid-2025, introduced a video foundation model built on a Diffusion Transformer architecture with multi-source data curation, video-specific RLHF (reinforcement learning from human feedback), and multi-stage distillation that achieved roughly 10x inference speedup. It generates 5-second 1080p video in about 41 seconds on an NVIDIA L20. Version 1.5 pro added a dual-branch Diffusion Transformer with a cross-modal joint module, enabling native audio-video generation with multilingual lip-sync and cinematic camera control. Seedance 2.0, the latest release, takes a unified multimodal approach: it accepts up to 9 images, 3 videos, and 3 audio files as combined input, producing 4 to 15-second clips with auto-generated sound effects. Its standout feature is reference-based control, where users can feed a reference video and the model will replicate its camera movements, lighting, and pacing while swapping characters or extending scenes.
Seedance 2.0 compresses what previously required separate tools for video generation, audio synthesis, and editing into a single model. For advertising, short-form content, and storyboarding, this reduces both cost and turnaround time substantially. The model’s ability to faithfully reproduce visual styles from reference material is so precise that Disney, SAG-AFTRA, and the Motion Picture Association have already issued cease-and-desist letters over unauthorized replication of copyrighted characters.
The copyright backlash highlights a deeper shift. Generative video models are now good enough that legal and ethical frameworks, not technical limitations, are the binding constraint on what gets produced. The gap between “technically possible” and “legally permissible” in AI-generated media has never been wider.
Sources:
- ByteDance Seed Models
- Seedance 2.0 Model Page
- Seedance 1.0 Technical Report (arXiv:2506.09113)
- Seedance 1.5 pro Technical Report (arXiv:2512.13507)
- The Decoder: Seedance 2.0 Coverage
Disclaimer: For information only. Accuracy or completeness not guaranteed. Illegal use prohibited. Not professional advice or solicitation. Read more: /terms-of-service
Reuse
Citation
@misc{kabui2026,
author = {{Kabui, Charles}},
title = {ByteDance {Seedance:} {Multimodal} {Video} {Generation}
{Reaches} a {New} {Threshold}},
date = {2026-02-16},
url = {https://toknow.ai/posts/bytedance-seedance-multimodal-video-generation/},
langid = {en-GB}
}