Archiving 1TB/Month: Why I Built Blober.io and What I Learned About “Vibe Coding”
Generally, I have found the following to be true about AI-assisted solutions in all domains:
- AI is good for:
- Drafting (kick starting a new project, templating, Generating a new document, etc)
- Proofreading (writing tests, debugging errors, etc)
- Manipulation (summarizing text, rephrasing a document, remixing the tone or theme of a text block, improving existing code, etc)
- AI saves you money in the short run (you dont need a website designer), but compensates by wasting time (you spend all the time prompting and tuning a design)
Simply speaking, AI is best used as a multiplier of existing skills, not a replacement for them.
As engineers, we often pride ourselves on the “elegance” of our scripts. For months, I managed a 1TB/month pipeline of media assets (archiving them to Azure Blob Storage) using a custom Python script. It worked fairly well but had its limitations.
Below is the script snippet I used to kick off transfers:
#!/usr/bin/env python3
"""
Resumable File Upload Script
Uploads files from specified glob patterns with resume capability, storage tiers, and configurable logging.
"""
import argparse
import concurrent.futures
import glob
import hashlib
import json
import logging
import os
import sys
import threading
import time
import traceback
from datetime import datetime
from typing import Dict, List, Optional, Tuple
import boto3
from azure.storage.blob import BlobServiceClient, StandardBlobTier
from azure.core.exceptions import ResourceExistsError
from wakepy import keep
# You'll need to install these dependencies:
# python3 -m venv venv
# source venv/bin/activate
# python -m pip install --upgrade pip
# pip install azure-storage-blob boto3 paramiko wakepy
# python upload_script.py config_sample.json --dry-run
# Choose the appropriate client based on your storage type
def get_file_timestamps(filepath: str) -> Tuple[float, float, float]:
"""
Get file timestamps: created, modified, accessed.
Args:
filepath (str): Path to the file
Returns:
Tuple: (created, modified, accessed)
On Unix systems, 'created' is estimated as min(ctime, mtime)
"""
if not os.path.exists(filepath):
raise FileNotFoundError(f"File not found: {filepath}")
stat_info = os.stat(filepath)
# On Unix, estimate creation time as min of ctime and mtime
# On Windows, st_ctime is actual creation time
if os.name == "nt": # Windows
created = stat_info.st_ctime
else: # Unix-like systems (Linux, macOS)
created = min(stat_info.st_ctime, stat_info.st_mtime)
modified = stat_info.st_mtime
accessed = stat_info.st_atime
return (created, modified, accessed)
class UploadLogger:
"""Custom logger with configurable console and file log levels"""
def __init__(self, log_file: str, console_level: int = 1, file_level: int = 3):
self.console_level = console_level
self.file_level = file_level
self.log_file = log_file
# Create logger
self.logger = logging.getLogger("upload_logger")
self.logger.setLevel(logging.DEBUG)
self.logger.handlers = [] # Clear any existing handlers
# Setup file handler if file logging is enabled
if file_level > 0:
os.makedirs(os.path.dirname(log_file), exist_ok=True)
file_handler = logging.FileHandler(log_file, encoding="utf-8")
file_formatter = logging.Formatter(
"%(asctime)s - %(levelname)s - %(message)s", datefmt="%Y-%m-%d %H:%M:%S"
)
file_handler.setFormatter(file_formatter)
self.logger.addHandler(file_handler)
# Setup console handler if console logging is enabled
if console_level > 0:
console_handler = logging.StreamHandler(sys.stdout)
console_formatter = logging.Formatter("%(message)s")
console_handler.setFormatter(console_formatter)
self.logger.addHandler(console_handler)
def log(
self,
level: int,
message: str,
console_only: bool = False,
file_only: bool = False,
):
"""Log message based on level and configuration"""
if level == 0:
return
# Determine if we should log to console and/or file
log_to_console = not file_only and self.console_level >= level
log_to_file = not console_only and self.file_level >= level
if not (log_to_console or log_to_file):
return
# Map level to logging level
log_level_map = {
1: logging.INFO, # Status bar - whole process
2: logging.INFO, # Status bar - success/failure
3: logging.ERROR, # Detailed errors
4: logging.WARNING, # Warnings
5: logging.INFO, # General info
6: logging.DEBUG, # Everything
}
py_level = log_level_map.get(level, logging.INFO)
# Create temporary logger for this message
temp_logger = logging.getLogger(f"temp_{level}")
temp_logger.handlers = []
temp_logger.setLevel(logging.DEBUG)
if log_to_console and not file_only:
console_handler = logging.StreamHandler(sys.stdout)
console_handler.setFormatter(logging.Formatter("%(message)s"))
temp_logger.addHandler(console_handler)
if log_to_file and not console_only and self.file_level > 0:
file_handler = logging.FileHandler(self.log_file, encoding="utf-8")
file_handler.setFormatter(
logging.Formatter(
"%(asctime)s - LEVEL%(levelname)s - %(message)s".replace(
"%(levelname)s", str(level)
),
datefmt="%Y-%m-%d %H:%M:%S",
)
)
temp_logger.addHandler(file_handler)
temp_logger.log(py_level, message)
# Clean up handlers
for handler in temp_logger.handlers:
handler.close()
temp_logger.handlers = []
class UploadStatus:
"""Manages upload status and resume functionality"""
def __init__(self, status_file: str):
self.status_file = status_file
self.status = self._load_status()
def _load_status(self) -> Dict:
"""Load existing status or create new one"""
if os.path.exists(self.status_file):
try:
with open(self.status_file, "r", encoding="utf-8") as f:
return json.load(f)
except (json.JSONDecodeError, IOError):
pass
return {
"session_id": self._generate_session_id(),
"started_at": datetime.now().isoformat(),
"completed_files": {},
"failed_files": {},
"total_files": 0,
"total_size": 0,
"uploaded_files": 0,
"uploaded_size": 0,
"current_pattern": None,
"patterns_completed": [],
}
def _generate_session_id(self) -> str:
"""Generate unique session ID"""
return hashlib.md5(f"{datetime.now().isoformat()}".encode()).hexdigest()[:8]
def save(self):
"""Save current status to file"""
os.makedirs(os.path.dirname(self.status_file), exist_ok=True)
with open(self.status_file, "w", encoding="utf-8") as f:
json.dump(self.status, f, indent=2, ensure_ascii=False)
def mark_file_completed(self, file_path: str, file_size: int, checksum: str):
"""Mark file as successfully uploaded"""
if file_path in self.status["failed_files"]:
del self.status["failed_files"][file_path]
self.status["completed_files"][file_path] = {
"size": file_size,
"checksum": checksum,
"uploaded_at": datetime.now().isoformat(),
}
self.status["uploaded_files"] += 1
self.status["uploaded_size"] += file_size
self.save()
def mark_file_failed(self, file_path: str, error: str):
"""Mark file as failed"""
self.status["failed_files"][file_path] = {
"error": error,
"failed_at": datetime.now().isoformat(),
}
self.save()
def is_file_completed(self, file_path: str) -> bool:
"""Check if file was already uploaded"""
return file_path in self.status["completed_files"]
def set_totals(self, total_files: int, total_size: int):
"""Set total files and size"""
self.status["total_files"] = total_files
self.status["total_size"] = total_size
self.save()
class StorageUploader:
"""Base class for different storage providers"""
def __init__(
self,
connection_string: str,
logger: UploadLogger,
storage_tier: str = "standard",
):
self.connection_string = connection_string
self.logger = logger
self.storage_tier = storage_tier
self.client = None
def get_supported_tiers(self) -> List[str]:
"""Return list of supported storage tiers"""
raise NotImplementedError
def validate_tier(self) -> bool:
"""Validate if the configured tier is supported"""
supported = self.get_supported_tiers()
if self.storage_tier not in supported:
self.logger.log(
3,
f"Unsupported storage tier '{self.storage_tier}'. Supported tiers: {supported}",
)
return False
return True
def connect(self):
"""Initialize connection to storage"""
raise NotImplementedError
def upload_file(self, local_path: str, remote_path: str) -> bool:
"""Upload a file to storage with specified tier"""
raise NotImplementedError
def get_file_checksum(self, file_path: str) -> str:
"""Calculate file checksum"""
hash_md5 = hashlib.md5()
try:
with open(file_path, "rb") as f:
for chunk in iter(lambda: f.read(4096), b""):
hash_md5.update(chunk)
return hash_md5.hexdigest()
except Exception as e:
self.logger.log(3, f"Error calculating checksum for {file_path}: {str(e)}")
return ""
class AzureBlobUploader(StorageUploader):
"""Azure Blob Storage uploader with tier support"""
def get_supported_tiers(self) -> List[str]:
return ["hot", "cold", "cool", "archive"]
def connect(self):
try:
# Create BlobServiceClient with optimized connection settings
# Using only well-supported parameters for better compatibility
self.client = BlobServiceClient.from_connection_string(
self.connection_string,
# Optimize connection settings for better performance
connection_timeout=60, # Connection timeout
read_timeout=300, # Read timeout for large files
max_block_size=4*1024*1024, # 4MB blocks
max_page_size=4*1024*1024, # 4MB pages
)
# Validate tier
if not self.validate_tier():
return False
# Map tier names to Azure enum
self.tier_map = {
"hot": StandardBlobTier.Hot,
"cold": StandardBlobTier.Cold,
"cool": StandardBlobTier.Cool,
"archive": StandardBlobTier.Archive,
}
self.logger.log(
5, f"Connected to Azure Blob Storage with tier: {self.storage_tier}"
)
return True
except Exception as e:
self.logger.log(3, f"Failed to connect to Azure Blob Storage: {str(e)}")
return False
def upload_file(self, local_path: str, remote_path: str) -> bool:
try:
# Extract container and blob name from remote path
parts = remote_path.strip("/").split("/", 1)
if len(parts) != 2:
raise ValueError(f"Invalid Azure blob path: {remote_path}")
container_name, blob_name = parts
blob_client = self.client.get_blob_client(
container=container_name, blob=blob_name
)
# Get file size to determine upload strategy
file_size = os.path.getsize(local_path)
# Use dynamic chunk size based on file size for optimal performance
if file_size < 100 * 1024 * 1024: # < 100MB
chunk_size = 4 * 1024 * 1024 # 4MB chunks
elif file_size < 1024 * 1024 * 1024: # < 1GB
chunk_size = 8 * 1024 * 1024 # 8MB chunks
else: # >= 1GB
chunk_size = 16 * 1024 * 1024 # 16MB chunks
# For files larger than 64MB, use staged upload (multipart)
if file_size > 64 * 1024 * 1024:
self._upload_large_file(blob_client, local_path, chunk_size)
else:
# For smaller files, use direct upload but with better parameters
with open(local_path, "rb") as data:
blob_client.upload_blob(
data,
overwrite=True,
standard_blob_tier=self.tier_map[self.storage_tier],
max_concurrency=4, # Allow concurrent connections
timeout=300, # 5 minute timeout
)
self.logger.log(
6,
f"Successfully uploaded {local_path} to {remote_path} (tier: {self.storage_tier})",
)
return True
except Exception as e:
self.logger.log(3, f"Failed to upload {local_path}: {str(e)}")
return False
def _upload_large_file(self, blob_client, local_path: str, chunk_size: int):
"""Upload large files using staged upload for better performance"""
import uuid
block_list = []
with open(local_path, "rb") as data:
block_index = 0
while True:
chunk = data.read(chunk_size)
if not chunk:
break
# Create unique block ID
block_id = str(uuid.uuid4()).replace('-', '')
block_list.append(block_id)
# Upload block
blob_client.stage_block(
block_id=block_id,
data=chunk,
timeout=300
)
block_index += 1
# Commit all blocks
blob_client.commit_block_list(
block_list,
standard_blob_tier=self.tier_map[self.storage_tier],
timeout=300
)
class S3Uploader(StorageUploader):
"""AWS S3 uploader with storage class support"""
def get_supported_tiers(self) -> List[str]:
return [
"standard",
"reduced_redundancy",
"standard_ia",
"onezone_ia",
"glacier",
"deep_archive",
"intelligent_tiering",
]
def connect(self):
try:
# Parse connection string for AWS credentials
# Format: "aws_access_key_id=XXX;aws_secret_access_key=XXX;region=XXX"
creds = dict(
item.split("=", 1) for item in self.connection_string.split(";")
)
self.client = boto3.client(
"s3",
aws_access_key_id=creds.get("aws_access_key_id"),
aws_secret_access_key=creds.get("aws_secret_access_key"),
region_name=creds.get("region", "us-east-1"),
)
# Validate tier
if not self.validate_tier():
return False
# Map tier names to S3 storage classes
self.tier_map = {
"standard": "STANDARD",
"reduced_redundancy": "REDUCED_REDUNDANCY",
"standard_ia": "STANDARD_IA",
"onezone_ia": "ONEZONE_IA",
"glacier": "GLACIER",
"deep_archive": "DEEP_ARCHIVE",
"intelligent_tiering": "INTELLIGENT_TIERING",
}
self.logger.log(
5, f"Connected to AWS S3 with storage class: {self.storage_tier}"
)
return True
except Exception as e:
self.logger.log(3, f"Failed to connect to AWS S3: {str(e)}")
return False
def upload_file(self, local_path: str, remote_path: str) -> bool:
try:
# Extract bucket and key from remote path
parts = remote_path.strip("/").split("/", 1)
if len(parts) != 2:
raise ValueError(f"Invalid S3 path: {remote_path}")
bucket_name, key = parts
# Upload with specified storage class
extra_args = {"StorageClass": self.tier_map[self.storage_tier]}
self.client.upload_file(local_path, bucket_name, key, ExtraArgs=extra_args)
self.logger.log(
6,
f"Successfully uploaded {local_path} to s3://{bucket_name}/{key} (class: {self.storage_tier})",
)
return True
except Exception as e:
self.logger.log(3, f"Failed to upload {local_path}: {str(e)}")
return False
class FileUploader:
"""Main file upload orchestrator"""
def __init__(self, config: Dict):
self.config = config
self.logger = UploadLogger(
self.config["log_file"],
self.config.get("console_log_level", 1),
self.config.get("file_log_level", 3),
)
self.status = UploadStatus(self.config["status_file"])
self.uploader = self._create_uploader()
# Store pattern info for path generation
self.pattern_base_paths = self._extract_pattern_base_paths()
# Configure parallel uploads (default to 3 concurrent uploads)
self.max_workers = self.config.get("max_parallel_uploads", 3)
# Thread lock for status updates
self._status_lock = threading.Lock()
def _create_uploader(self) -> StorageUploader:
"""Create appropriate uploader based on connection string"""
conn_str = self.config["connection_string"].lower()
storage_tier = self.config.get("storage_tier", "standard")
if (
"blob.core.windows.net" in conn_str
or "defaultendpointsprotocol" in conn_str
):
return AzureBlobUploader(
self.config["connection_string"], self.logger, storage_tier
)
elif "aws_access_key_id" in conn_str:
return S3Uploader(
self.config["connection_string"], self.logger, storage_tier
)
else:
# Add more storage providers as needed
self.logger.log(3, f"Unsupported storage type in connection string")
sys.exit(1)
def _extract_pattern_base_paths(self) -> Dict[str, str]:
"""Extract base paths from patterns for later use in path generation"""
base_paths = {}
for pattern_item in self.config["file_search_patterns"]:
if isinstance(pattern_item, list):
# Format: [pattern, base_path]
if len(pattern_item) >= 2:
pattern, base_path = pattern_item[0], pattern_item[1]
base_paths[pattern] = os.path.normpath(base_path)
elif len(pattern_item) == 1:
# Only pattern provided, no base path
pattern = pattern_item[0]
base_paths[pattern] = None
else:
# String format (legacy)
pattern = pattern_item
base_paths[pattern] = None
return base_paths
def _find_files_from_patterns(self) -> List[Tuple[str, Optional[str]]]:
"""Find files matching all glob patterns, returning (file_path, base_path) tuples"""
all_files = {} # Use dict to avoid duplicates and store base_path info
for pattern_item in self.config["file_search_patterns"]:
if isinstance(pattern_item, list):
# Format: [pattern, base_path] or [pattern]
pattern = pattern_item[0]
base_path = pattern_item[1] if len(pattern_item) >= 2 else None
else:
# String format (legacy)
pattern = pattern_item
base_path = None
self.logger.log(6, f"Processing pattern: {pattern} (base: {base_path})")
try:
# Use glob to find matching files
matches = glob.glob(pattern, recursive=True)
files = [m for m in matches if os.path.isfile(m)]
self.logger.log(5, f"Pattern '{pattern}' matched {len(files)} files")
for file_path in files:
# Store with normalized paths and base path info
normalized_path = os.path.normpath(file_path)
normalized_base = os.path.normpath(base_path) if base_path else None
all_files[normalized_path] = normalized_base
self.logger.log(6, f"Found: {file_path}")
except Exception as e:
self.logger.log(4, f"Error processing pattern '{pattern}': {str(e)}")
continue
file_list = [(path, base) for path, base in all_files.items()]
self.logger.log(5, f"Total unique files found: {len(file_list)}")
return file_list
def _get_upload_path(self, local_path: str, base_path: Optional[str] = None) -> str:
"""Generate remote upload path based on upload directory expression"""
try:
upload_expr = self.config["upload_directory_expression"]
# Get file and directory information
filename = os.path.basename(local_path)
file_dir = os.path.dirname(local_path)
# Calculate base_dir based on base_path
if base_path and os.path.commonpath([local_path, base_path]) == base_path:
# File is under the base path
relative_to_base = os.path.relpath(local_path, base_path)
base_dir = os.path.dirname(relative_to_base)
# Normalize path separators and remove current directory marker
base_dir = base_dir.replace("\\", "/")
if base_dir == ".":
base_dir = ""
else:
# Fallback to immediate parent directory if no base_path or file not under base_path
base_dir = os.path.basename(file_dir) if file_dir else ""
# Remove leading or trailing slashes
base_dir = base_dir.strip("/")
# Create underscore version of base_dir
base_dir_underscore = base_dir.replace("/", "_")
# Split filename into name and extension
filename_no_ext, file_ext = os.path.splitext(filename)
file_ext = file_ext.lstrip(".") # Remove leading dot
# Get file size information
try:
file_size = os.path.getsize(local_path)
file_size_mb = round(file_size / (1024 * 1024), 2)
except OSError:
file_size = 0
file_size_mb = 0
# Get file timestamps
try:
created, modified, accessed = get_file_timestamps(local_path)
# File creation time
file_created = datetime.fromtimestamp(created)
file_created_str = file_created.strftime("%Y-%m-%d")
file_created_datetime_str = file_created.strftime("%Y-%m-%d_%H-%M-%S")
# File modification time
file_modified = datetime.fromtimestamp(modified)
file_modified_str = file_modified.strftime("%Y-%m-%d")
file_modified_datetime_str = file_modified.strftime("%Y-%m-%d_%H-%M-%S")
# File access time
file_accessed = datetime.fromtimestamp(accessed)
file_accessed_str = file_accessed.strftime("%Y-%m-%d")
file_accessed_datetime_str = file_accessed.strftime("%Y-%m-%d_%H-%M-%S")
except OSError:
# Fallback to current time if file timestamps unavailable
current_time = datetime.now()
file_created_str = current_time.strftime("%Y-%m-%d")
file_created_datetime_str = current_time.strftime("%Y-%m-%d_%H-%M-%S")
file_modified_str = current_time.strftime("%Y-%m-%d")
file_modified_datetime_str = current_time.strftime("%Y-%m-%d_%H-%M-%S")
file_accessed_str = current_time.strftime("%Y-%m-%d")
file_accessed_datetime_str = current_time.strftime("%Y-%m-%d_%H-%M-%S")
# Variable substitution
upload_path = upload_expr
# Current datetime variables
upload_path = upload_path.replace(
"{date}", datetime.now().strftime("%Y-%m-%d")
)
upload_path = upload_path.replace(
"{datetime}", datetime.now().strftime("%Y-%m-%d_%H-%M-%S")
)
# File datetime variables
upload_path = upload_path.replace("{file_created}", file_created_str)
upload_path = upload_path.replace(
"{file_created_datetime}", file_created_datetime_str
)
upload_path = upload_path.replace("{file_modified}", file_modified_str)
upload_path = upload_path.replace(
"{file_modified_datetime}", file_modified_datetime_str
)
upload_path = upload_path.replace("{file_accessed}", file_accessed_str)
upload_path = upload_path.replace(
"{file_accessed_datetime}", file_accessed_datetime_str
)
# Path and filename variables
upload_path = upload_path.replace("{filename}", filename)
upload_path = upload_path.replace("{filename_no_ext}", filename_no_ext)
upload_path = upload_path.replace("{file_ext}", file_ext)
upload_path = upload_path.replace("{base_dir}", base_dir)
upload_path = upload_path.replace(
"{base_dir_underscore}", base_dir_underscore
)
# File size variables
upload_path = upload_path.replace("{file_size}", str(file_size))
upload_path = upload_path.replace("{file_size_mb}", str(file_size_mb))
return upload_path.replace("\\", "/").strip("/").replace("//", "/")
except Exception as e:
self.logger.log(
3, f"Error generating upload path for {local_path}: {str(e)}"
)
return f"uploads/{os.path.basename(local_path)}"
def _get_all_files_with_info(
self, file_data: List[Tuple[str, Optional[str]]]
) -> Tuple[List[Tuple[str, str, int]], int]:
"""Get all files with their upload paths and sizes"""
files = []
total_size = 0
for file_path, base_path in file_data:
try:
if not os.path.exists(file_path):
self.logger.log(4, f"File not found: {file_path}")
continue
file_size = os.path.getsize(file_path)
upload_path = self._get_upload_path(file_path, base_path)
files.append((file_path, upload_path, file_size))
total_size += file_size
self.logger.log(
6, f"File: {file_path} -> {upload_path} ({file_size} bytes)"
)
except OSError as e:
self.logger.log(4, f"Cannot access file {file_path}: {str(e)}")
continue
except Exception as e:
self.logger.log(3, f"Error processing file {file_path}: {str(e)}")
continue
self.logger.log(
5, f"Processed {len(files)} files totaling {total_size:,} bytes"
)
return files, total_size
def _format_size(self, size_bytes: int) -> str:
"""Format bytes as human readable size"""
for unit in ["B", "KB", "MB", "GB", "TB"]:
if size_bytes < 1024.0:
return f"{size_bytes:.1f} {unit}"
size_bytes /= 1024.0
return f"{size_bytes:.1f} PB"
def _format_progress(
self, current: int, total: int, size_current: int, size_total: int
) -> str:
"""Format progress string"""
file_pct = (current / total * 100) if total > 0 else 0
size_pct = (size_current / size_total * 100) if size_total > 0 else 0
return (
f"Progress: {current}/{total} files ({file_pct:.1f}%) | "
f"{self._format_size(size_current)}/{self._format_size(size_total)} ({size_pct:.1f}%)"
)
def _show_supported_tiers(self):
"""Display supported tiers for the current storage provider"""
supported_tiers = self.uploader.get_supported_tiers()
current_tier = self.config.get("storage_tier", "standard")
self.logger.log(5, f"Storage provider supported tiers: {supported_tiers}")
self.logger.log(5, f"Configured tier: {current_tier}")
if current_tier not in supported_tiers:
self.logger.log(
3, f"ERROR: Configured tier '{current_tier}' is not supported!"
)
self.logger.log(3, f"Please choose from: {supported_tiers}")
return False
return True
def _upload_single_file(self, file_info: Tuple[str, str, int], current_stats: Dict) -> bool:
"""Upload a single file (thread-safe)"""
local_path, upload_path, file_size = file_info
# Skip if already completed
if self.status.is_file_completed(local_path):
self.logger.log(6, f"Skipping already uploaded file: {local_path}")
return True
try:
self.logger.log(
5,
f"Uploading: {os.path.basename(local_path)} ({self._format_size(file_size)})",
)
self.logger.log(6, f"Local: {local_path}")
self.logger.log(6, f"Remote: {upload_path}")
# Calculate checksum before upload
self.logger.log(6, f"Calculating checksum for {local_path}")
checksum = self.uploader.get_file_checksum(local_path)
# Upload file
upload_start = time.time()
if self.uploader.upload_file(local_path, upload_path):
upload_time = time.time() - upload_start
speed = file_size / upload_time if upload_time > 0 else 0
# Thread-safe status update
with self._status_lock:
self.status.mark_file_completed(local_path, file_size, checksum)
current_stats['uploaded'] += 1
current_stats['size'] += file_size
self.logger.log(
2,
f"Uploaded: {os.path.basename(local_path)} ({self._format_size(speed)}/s)",
)
self.logger.log(
6, f"Upload time: {upload_time:.2f}s, Checksum: {checksum}"
)
return True
else:
with self._status_lock:
self.status.mark_file_failed(local_path, "Upload failed")
self.logger.log(2, f"Failed: {os.path.basename(local_path)}")
return False
except Exception as e:
error_msg = f"Upload error: {str(e)}"
with self._status_lock:
self.status.mark_file_failed(local_path, error_msg)
self.logger.log(3, f"Error uploading {local_path}: {str(e)}")
self.logger.log(6, f"Traceback: {traceback.format_exc()}")
self.logger.log(2, f"Failed: {os.path.basename(local_path)}")
return False
def upload_files(self):
"""Main upload process"""
try:
# Connect to storage
self.logger.log(1, "Initializing upload process...")
# Show supported tiers
if not self._show_supported_tiers():
return False
if not self.uploader.connect():
self.logger.log(3, "Failed to connect to storage")
return False
# Find files from patterns
self.logger.log(1, "Scanning for files...")
self.logger.log(
5, f"Search patterns: {self.config['file_search_patterns']}"
)
file_data = self._find_files_from_patterns()
if not file_data:
self.logger.log(2, "No files found matching search patterns")
return False
# Get file information
self.logger.log(1, "Processing file information...")
all_files, total_size = self._get_all_files_with_info(file_data)
if not all_files:
self.logger.log(2, "No valid files found to upload")
return True
# Update status with totals
self.status.set_totals(len(all_files), total_size)
# Log initial status
completed_count = len(self.status.status["completed_files"])
completed_size = sum(
f["size"] for f in self.status.status["completed_files"].values()
)
remaining_files = len(all_files) - completed_count
remaining_size = total_size - completed_size
if completed_count > 0:
self.logger.log(
1, f"Resuming upload: {completed_count} files already completed"
)
self.logger.log(
5, f"Already uploaded: {self._format_size(completed_size)}"
)
self.logger.log(
1,
f"Starting upload of {remaining_files} files ({self._format_size(remaining_size)}) to tier: {self.config['storage_tier']}",
)
self.logger.log(
5, f"Using {self.max_workers} parallel upload threads"
)
# Upload files with parallel processing
start_time = time.time()
current_stats = {'uploaded': completed_count, 'size': completed_size}
# Filter out already completed files
files_to_upload = [
file_info for file_info in all_files
if not self.status.is_file_completed(file_info[0])
]
try:
if self.max_workers == 1:
# Sequential upload for single thread
for file_info in files_to_upload:
self._upload_single_file(file_info, current_stats)
# Show progress
progress = self._format_progress(
current_stats['uploaded'], len(all_files),
current_stats['size'], total_size
)
self.logger.log(1, progress)
else:
# Parallel upload
with concurrent.futures.ThreadPoolExecutor(max_workers=self.max_workers) as executor:
# Submit all upload tasks
future_to_file = {
executor.submit(self._upload_single_file, file_info, current_stats): file_info
for file_info in files_to_upload
}
# Process completed uploads
for future in concurrent.futures.as_completed(future_to_file):
file_info = future_to_file[future]
try:
success = future.result()
# Show progress (thread-safe)
with self._status_lock:
progress = self._format_progress(
current_stats['uploaded'], len(all_files),
current_stats['size'], total_size
)
self.logger.log(1, progress)
except Exception as e:
local_path = file_info[0]
self.logger.log(3, f"Thread error for {local_path}: {str(e)}")
except KeyboardInterrupt:
self.logger.log(
2, "\nUpload interrupted by user. Status saved for resume."
)
return False
# Final status
total_time = time.time() - start_time
failed_count = len(self.status.status["failed_files"])
success_count = len(self.status.status["completed_files"])
final_uploaded_size = current_stats['size']
self.logger.log(1, f"Upload completed in {total_time:.2f} seconds!")
self.logger.log(
1, f"Success: {success_count} files | Failed: {failed_count} files"
)
self.logger.log(
1, f"Total data uploaded: {self._format_size(final_uploaded_size)}"
)
if failed_count > 0:
self.logger.log(2, f"Failed files:")
for failed_file, info in self.status.status["failed_files"].items():
self.logger.log(
2, f" - {os.path.basename(failed_file)}: {info['error']}"
)
self.logger.log(6, f" Full path: {failed_file}")
return failed_count == 0
except Exception as e:
self.logger.log(3, f"Critical error in upload process: {str(e)}")
self.logger.log(3, f"Traceback: {traceback.format_exc()}")
return False
def load_config(config_path: str) -> Dict:
"""Load configuration from JSON file"""
try:
with open(config_path, "r", encoding="utf-8") as f:
config = json.load(f)
required_fields = [
"connection_string",
"file_search_patterns",
"upload_directory_expression",
"status_file",
"log_file",
]
for field in required_fields:
if field not in config:
raise ValueError(f"Missing required config field: {field}")
# Ensure file_search_patterns is a list
if not isinstance(config["file_search_patterns"], list):
raise ValueError("file_search_patterns must be an array")
# Set default storage tier if not specified
if "storage_tier" not in config:
config["storage_tier"] = "standard"
return config
except Exception as e:
print(f"Error loading config: {str(e)}")
sys.exit(1)
def create_sample_config():
"""Create a sample configuration file"""
sample_config = {
"connection_string": "DefaultEndpointsProtocol=https;AccountName=mystorageaccount;AccountKey=mykey;EndpointSuffix=core.windows.net",
"file_search_patterns": [
[
"/home/user/Downloads/UploadTest/**/*.*",
"/home/user/Downloads/UploadTest",
],
["/home/user/Documents/Projects/**/*.pdf", "/home/user/Documents/Projects"],
"/home/user/Pictures/Vacation/*.{jpg,png,gif}",
["/home/user/Videos/Family/**/*.{mp4,avi,mov}"],
],
"upload_directory_expression": "backups/{file_modified}/{base_dir}/{filename_no_ext}_{file_size_mb}mb.{file_ext}",
"storage_tier": "archive",
"max_parallel_uploads": 3,
"status_file": "./upload_status/status.json",
"log_file": "./upload_logs/upload.log",
"console_log_level": 2,
"file_log_level": 5,
"_comments": {
"connection_string": "Storage connection string (Azure Blob, AWS S3, etc.)",
"file_search_patterns": "Array of patterns. Can be strings or [pattern, base_path] arrays. Base path is optional and used for calculating {base_dir}",
"upload_directory_expression": "Template for remote upload path with variable substitution",
"storage_tier": "Storage tier for uploads (varies by provider)",
"max_parallel_uploads": "Number of concurrent upload threads (1-10, default: 3). Higher values = faster uploads but more resource usage",
"log_levels": "0=disabled, 1=status bar, 2=success/failure, 3=errors, 4=warnings, 5=info, 6=debug",
"path_variables": {
"current_datetime": {
"date": "Current date (YYYY-MM-DD) - e.g., 2025-08-31",
"datetime": "Current date and time (YYYY-MM-DD_HH-MM-SS) - e.g., 2025-08-31_14-30-45",
},
"file_datetime": {
"file_created": "File creation date (YYYY-MM-DD) - e.g., 2024-12-15",
"file_created_datetime": "File creation date and time (YYYY-MM-DD_HH-MM-SS) - e.g., 2024-12-15_09-15-30",
"file_modified": "File modification date (YYYY-MM-DD) - e.g., 2025-01-20",
"file_modified_datetime": "File modification date and time (YYYY-MM-DD_HH-MM-SS) - e.g., 2025-01-20_16-45-22",
"file_accessed": "File last accessed date (YYYY-MM-DD) - e.g., 2025-08-31",
"file_accessed_datetime": "File last accessed date and time (YYYY-MM-DD_HH-MM-SS) - e.g., 2025-08-31_12-00-15",
},
"file_info": {
"filename": "Complete filename with extension - e.g., document.pdf",
"filename_no_ext": "Filename without extension - e.g., document",
"file_ext": "File extension without dot - e.g., pdf",
"file_size": "File size in bytes - e.g., 1048576",
"file_size_mb": "File size in MB (rounded to 2 decimals) - e.g., 1.50",
},
"path_info": {
"base_dir": "Directory path from base path to file location with / separators - e.g., test2/test3",
"base_dir_underscore": "Directory path from base path to file location with _ separators - e.g., test2_test3",
},
},
"example_expressions": [
"archive/{file_created}/{base_dir}/{filename}",
"backup/{file_modified_datetime}/{base_dir_underscore}_{filename}",
"sorted/{file_ext}/{file_modified}/{base_dir}/{filename_no_ext}_{file_size_mb}mb.{file_ext}",
"timestamped/{file_created}_{file_modified}/{base_dir}/{filename}",
"organized/{file_ext}_files/{file_created}/{base_dir}/{filename}",
],
"supported_tiers": {
"azure": ["hot", "cool", "archive"],
"s3": [
"standard",
"reduced_redundancy",
"standard_ia",
"onezone_ia",
"glacier",
"deep_archive",
"intelligent_tiering",
],
},
},
}
with open("config_sample.json", "w", encoding="utf-8") as f:
json.dump(sample_config, f, indent=2, ensure_ascii=False)
print("Sample configuration created: config_sample.json")
print("\nExample connection strings:")
print(
"Azure Blob: DefaultEndpointsProtocol=https;AccountName=myaccount;AccountKey=mykey;EndpointSuffix=core.windows.net"
)
print(
"AWS S3: aws_access_key_id=AKIA...;aws_secret_access_key=...;region=us-east-1"
)
print("\nStorage Tiers:")
print("Azure: hot, cool, archive")
print(
"S3: standard, reduced_redundancy, standard_ia, onezone_ia, glacier, deep_archive, intelligent_tiering"
)
def show_tiers_command(config_path: str):
"""Show supported tiers for the configured storage provider"""
try:
uploader = FileUploader(load_config(config_path))
supported_tiers = uploader.uploader.get_supported_tiers()
current_tier = uploader.config.get("storage_tier", "standard")
print(f"Supported storage tiers: {supported_tiers}")
print(f"Current configured tier: {current_tier}")
if current_tier not in supported_tiers:
print(f"WARNING: Current tier '{current_tier}' is not supported!")
print(f"Please choose from: {supported_tiers}")
else:
print(f"✓ Current tier is valid")
except Exception as e:
print(f"Error checking tiers: {str(e)}")
def main():
"""Main entry point"""
parser = argparse.ArgumentParser(description="Resumable File Upload Script")
parser.add_argument("config", nargs="?", help="Configuration file path")
parser.add_argument(
"--create-sample", action="store_true", help="Create sample configuration file"
)
parser.add_argument(
"--show-tiers",
action="store_true",
help="Show supported storage tiers for configured provider",
)
parser.add_argument(
"--dry-run",
action="store_true",
help="Show what would be uploaded without actually uploading",
)
args = parser.parse_args()
if args.create_sample:
create_sample_config()
return
if not args.config:
print("Error: Configuration file required")
print("Usage: python upload_script.py config.json")
print(" python upload_script.py --create-sample")
print(" python upload_script.py config.json --show-tiers")
print(" python upload_script.py config.json --dry-run")
sys.exit(1)
if not os.path.exists(args.config):
print(f"Error: Configuration file '{args.config}' not found")
sys.exit(1)
if args.show_tiers:
show_tiers_command(args.config)
return
# Run upload or dry run
uploader = FileUploader(load_config(args.config))
if args.dry_run:
print("DRY RUN MODE - No files will be uploaded")
print("=" * 50)
# Show what would be uploaded
file_data = uploader._find_files_from_patterns()
all_files, total_size = uploader._get_all_files_with_info(file_data)
print(
f"Would upload {len(all_files)} files ({uploader._format_size(total_size)})"
)
print(f"Storage tier: {uploader.config['storage_tier']}")
print(f"Supported tiers: {uploader.uploader.get_supported_tiers()}")
print(
f"Upload directory expression: {uploader.config['upload_directory_expression']}"
)
print("\nSample files to upload:")
for i, (local_path, upload_path, file_size) in enumerate(
all_files[:10]
): # Show first 10
print(f" {i+1:2d}. {local_path}")
print(f" -> {upload_path}")
print(f" Size: {uploader._format_size(file_size)}")
# Show file timestamps for first few files
if i < 3:
try:
created, modified, accessed = get_file_timestamps(local_path)
created = datetime.fromtimestamp(created).strftime(
"%Y-%m-%d %H:%M:%S"
)
modified = datetime.fromtimestamp(modified).strftime(
"%Y-%m-%d %H:%M:%S"
)
accessed = datetime.fromtimestamp(accessed).strftime(
"%Y-%m-%d %H:%M:%S"
)
print(
f" Created: {created}, Modified: {modified}, Accessed: {accessed}"
)
except OSError:
pass
print()
if len(all_files) > 10:
print(f" ... and {len(all_files) - 10} more files")
return
success = uploader.upload_files()
sys.exit(0 if success else 1)
if __name__ == "__main__":
with keep.running():
main()To run the script, the following dependencies were required:
python3 -m venv venv # Create an enviromnemt
source venv/bin/activate
python -m pip install --upgrade pip
pip install azure-storage-blob boto3 paramiko wakepy{
"connection_string": "DefaultEndpointsProtocol=https;AccountName=mystorageaccount;AccountKey=mykey;EndpointSuffix=core.windows.net",
"file_search_patterns": [
[
"/home/user/Pictures/Vacation/*.{jpg,png,gif}",
"/home/user/Videos/Family/**/*.{mp4,avi,mov}"
]
],
"upload_directory_expression": "backup/{file_created}/{file_created_datetime}:{filename}",
"storage_tier": "archive",
"status_file": "./upload_status/status.json",
"log_file": "./upload_logs/upload.log",
"console_log_level": 2,
"file_log_level": 6,
}Then, you’d run the script: python upload_script.py config_sample.json --dry-run to preview the changes without uploading, and then when you are ready, you would do: python upload_script.py config_sample.json. This would upload the files matching the patterns to Azure Blob Storage, organizing them by their creation date, ending up with a structure like this:
backup/
├── 2025-12-24/
│ ├── 2025-12-24_08-24-02:DSC08007.jpg
│ └── 2025-12-24_09-15-45:IMG_1234.mp4
└── 2025-12-25/
├── 2025-12-25_10-05-30:HolidayPic.png
└── 2025-12-25_11-20-10:FamilyVideo.aviNow suppose you want to run this script every night at 2 AM? Thats another setup! If you want Upload to AWS S3 instead of Azure Blob? More changes! Over time, this script becomes very complex and hard to maintain. What if you need to run the same setup on Windows or MacOS? More setup work! And at the end of the day, python isn’t particularly well suited for async IO operations, so the performance is not optimal.
When you are dealing with high-volume archival, the script eventually hits a wall of operational debt. I realized I didn’t just need a transfer tool; I needed a state-aware workflow engine.
I spent two weeks over the Christmas break building Blober.io. Here is the technical breakdown of the project and my honest take on the “Vibe Coding” approach that made a 14-day delivery possible.
The Problem
Cloud providers (especially Azure Blob) are phenomenal for scale but terrible for discovery. If you dump 10,000 files into a flat container, you have essentially created a data graveyard.
I needed my files organized deterministically as they were uploaded. My preferred pattern: container/{file_created_date}/{file_created_datetime}:{filename}
While rclone is the industry standard, achieving this level of metadata-aware path structure would require complex wrapper scripts. In Blober, this is a first-class primitive!
The Architecture: Local-First Workflow Model
Blober isn’t just a CLI wrapper. It uses a persistent Workflow/Task model backed by a local SQLite DB:
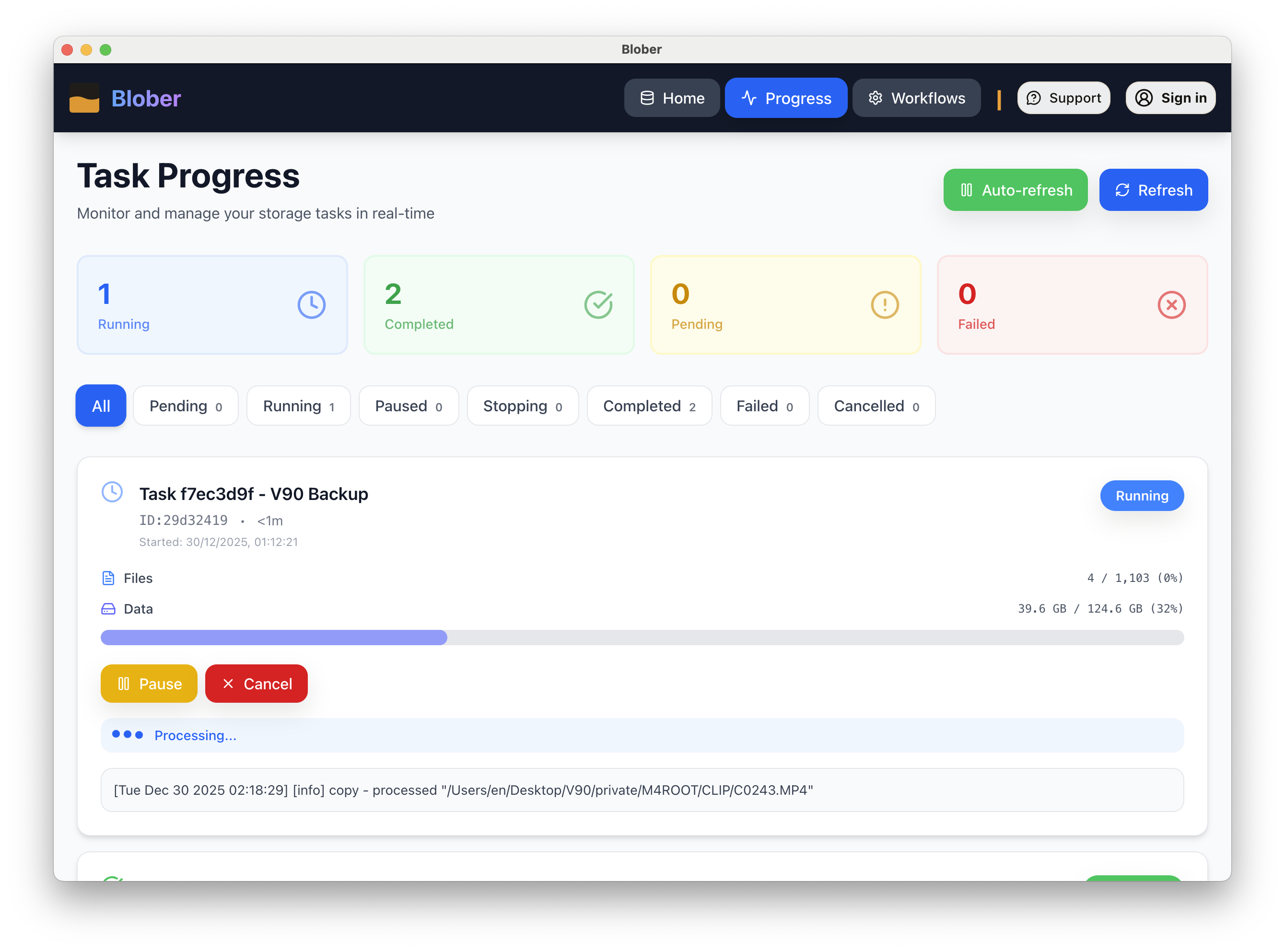
- Immutable Jobs: When a workflow triggers, Blober snapshots the configuration into a “Job.”
- The Executor: A background polling loop in Electron that picks up tasks and, crucially, manages power states to keep the machine awake until the transfer is 100% complete.
- Metadata Engine: We inspect file attributes via
stat()or provider APIs to inject variables like{file_created_date}or{file_size_mb}into the destination path in real-time.
Lessons from “Vibe Coding”
Building a full-stack desktop app in two weeks requires a different approach to development. I leaned heavily into AI-assisted “Vibe Coding,” and the results were enlightening.
1. The Tooling Hierarchy
Not all models are created equal for engineering:
- The Modifier: Claude 3.5 Sonnet remains the undisputed king for modifying existing, complex codebases without breaking state.
- The Designer: Gemini 3 is surprisingly creative with user layouts and User interfaces.
- The Baseline: Python and ReactJS are now so well-supported across all models that boilerplate is essentially a solved problem.
2. The “Deep Thinking” Trap
One of my biggest takeaways: Deep thinking/research models are often useless for code generation. When you ask a model to “think” too hard about a coding problem, it often results into an over-engineered, verbose logic that ignores the immediate context. Quick-thinking models (like Sonnet) are superior because they iterate at the speed of the developer’s intent.
3. The Prompt Engineering Hack
Without a strict framework, all models eventually drift into slopy code. My most successful prompt strategy is forcing the AI to plan before generating the code, by ending every prompt with:
“Before you start implementation and code generation, create a detailed multi-phase, multi-stage, and multi-step implementation plan. Before proceeding to each next phase, ask for my explicit consent.”
This “Pause-and-Evaluate” gate is the only way to prevent an AI from hallucinating a 500-line file that solves a 50-line problem.
4. The Economic Trade-off
Vibe coding is a double-edged sword:
- The Win: It saves significant capital, for example, you dont need to hire a UI/UX designer!
- The Loss: It is a massive time-sink. You trade “writing code” for “tuning prompts.You can spend hours perfecting a design.
Blober vs. rclone: An Honest Case
Blober is not intended to replace rclone. If you are running headless Linux servers with complex filter flags, stay with rclone.
Choose Blober if:
- You want a persistent history of every file moved (via the local DB).
- You need human-readable guardrails and conflict detection.
- You want metadata-aware pathing without writing custom bash/python wrappers.
What’s Next?
The “Christmas Challenge” version of Blober is live. I’m currently looking to add support for more cloud providers and move the sync implementation from “planned” to “production-ready.”
If you’re moving high volumes of data and find yourself fighting with scripts, I’d love for you to give Blober.io a spin. I’m looking for brutal feedback on the workflow model: does it solve your organizational debt?
Disclaimer: For information only. Accuracy or completeness not guaranteed. Illegal use prohibited. Not professional advice or solicitation. Read more: /terms-of-service
Reuse
Citation
@misc{kabui2025,
author = {{Kabui, Charles}},
title = {Vibe {Coding} {Challenge:} {The} {Art} and {The} {Skill}},
date = {2025-12-31},
url = {https://toknow.ai/posts/vibe-coding-challenge/},
langid = {en-GB}
}